Smart Cities, NFV, Data Security and fixing AI systems all provide delicious, nutritious brain-food in this month’s edition.
Making Sense of the City

The above quotation comes from a collaboration between Hong Kong Polytechnic University and AI Africa Labs, headed by Dr. Mohamed Abdul Rahman. In many societal situations today there is no shortage of data, but a lack of clean, reliable data sources and actionable intelligence arising from that data. The authors propose a framework to simply mine, clean, process, and validate social media in order to arrive at actionable intelligence for urban planners and managers. This involves a variety of machine learning techniques which, when implemented in a trial, produced usable outcomes that track changes in sentiment and community challenges over time.
6G Industrial Data Security
“I’m going to make a provocative prediction: 5G is the last of the monolithic, homogenous, pervasive Gs.” So said Steve Papa, CEO, Parallel Wireless at the 6GSymposium last month in this panel session. His point was that 5G will likely serve most users with a demand for mobility well enough, and that Beyond-5G networks will tend to have a wide diversity of specialised and localised use cases. Therefore, they would be deployed selectively, and with characteristics that differ depending on the use cases in demand locally.
By coincidence, an international group of researchers had been readying their paper “A Blockchain-based Secure Data Aggregation Strategy using 6G-enabled NIB for Industrial Applications,” for release at almost the same time. The authors’ driving assumption is that 6G in industrial settings is likely to be very much a localised solution, where the network essentially exists as software on premises as a “network-in-a-box” (NIB). This will contain services deployed directly on-site, keeping traffic as much as possible on premise. In itself this would, to a degree, support the management of data security and privacy. However, they also propose a new form of blockchain-based system called BPDC (Blockchain-based Privacy-aware Distributed Collection-oriented strategy for data aggregation).
The proposed system decomposes sensitive data and restricts access to it based on the reviewers’ levels of security permission, with “extensive simulation experiments [demonstrating] that the BPDC can obtain high throughput, low overhead, and privacy security.”
Various Virtualisation Visionaries Nail Neat NFV Notions
It’s been a busy period for researchers around the world aiming to make virtualised networks practical propositions. New reports are being published across a wide range of study areas designed to make Network Function Virtualisation (NFV) live up to its promise in the field.
For example, a team headed by Zhuqing Zhu of China’s USTC has been looking at what happens in networks where NFV platforms vary within the network, across virtual machines [VMs], docker containers, and programmable hardware accelerators. To date, most studies of the benefits of NFV have taken place in environments using only one type of platform; but in this paper they argue that different types of NFV platform have different strengths in terms of throughput or flexibility, and canny telcos should be able to take advantage of this to further improve how the network performs. Their experiments focus on service provisioning and, while not yet tested in a live environment, seem to support the theory.
Next, a team at Brazil’s Federal University of Rio Grande do Sul (UFRGS) have been tackling the problem of how, when a network slice is provisioned, both customers and network providers can monitor and manage aspects of the slice with a minimum of network overhead. Their solution is a system they call SWEETEN, and in this paper they outline in detail the nature of the problem and the solution and share a case study in a dynamic Centralised RAN (C-RAN) environment.
Meanwhile, a UAE-Canada collaboration has published “On Minimizing Synchronization Cost in NFV-based Environments.” They point out that, at times of heavier traffic, instances of the same function may need to be deployed in multiple virtual machines; However, “running the same network function in a distributed manner over multiple instances is challenging” and demands time and computing resources to synchronise those instances. The team proposes two things to minimise the time and resources needed for synchronisation:
- A technique to identify the optimal communication pattern between instances.
- A new virtual Synchronization Function that ensures consistency among a set of instances.
They demonstrate a significant reduction in time and computing resources, which for operators will add up to more responsive and energy-efficient networks.
Finally, while the other pieces of research operate within particular instances or network slices, a Greek team drawn from universities and industry has developed this paper on orchestrating cross-slice communication for edge computing. While a customer may (quite reasonably) only be concerned with their own service quality, the telco needs to be able to support all their customers’ services and slices; and, especially at the edge of the network, there is a risk of overall resource constraints impinging on service delivery. The paper discusses not only why one should implement a MANO-based, but edge-specific, orchestration architecture in terms of the business opportunities it creates, but also describes its composition and how it would work.
Practical Machine Learning Risk Mitigation for the Workplace
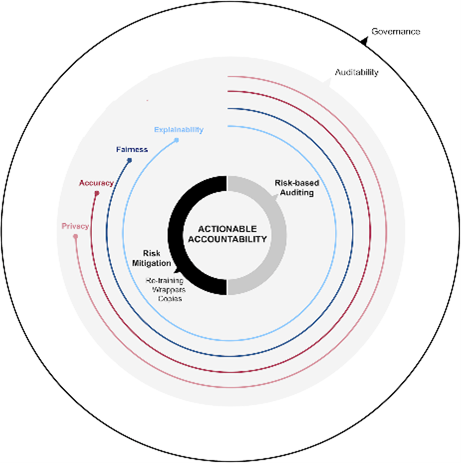
A group of researchers at Universitat de Barcelona and Universitat Ramon Llull released a paper sharing insights into the tricky challenge of accountability and risk mitigation in real-life Machine Learning (ML) systems. They included a case study which put some of their concepts into action credit-scoring in Mexico.
As they pointed out, “In general, there exists a gap between the theoretical proposals for accountability and the limitations that data scientists face inside a company environment. While the ML community has mainly focused on providing solutions for in-vitro settings, where both the data and the algorithms are readily accessible, most real-life situations do not conform to this ideal.”
This gap creates a variety of very real business problems.
Firstly: “We consider accountability to be ultimately an issue of trust, of the extent to which we can rely on our knowledge of the system, in terms of how it works and why it behaves the way it does.” If the company itself is unable to understand its ML systems, then it becomes much more difficult to correct any errors; for example, if the system is producing outcomes with an undesirable bias.
Moreover, “Accountability is therefore related to responsibility in the legal sense. If algorithms themselves cannot be made accountable of their decisions, there needs to be a clear legal subject or entity who will.” In other words, the allocation of corporate risk can change depending on the degree of accountability an ML system or components of it (such as training data providers, the algorithm developers etc. who may or may not be third-party suppliers) possess.
Uncertainty may also be introduced by the fact that businesses are not static, and nor are the environments in which they operate. “Data usually come from different sources and need to be enriched along the process. Models are not trained in a single run, but iteratively, and are deployed to constrained production environments through continuous integration,” they wrote. “This means that there are elements in the context of a model which are out of our control. As a result, a model may need to deal, for example, with change in the data, in the business needs or in the legal frameworks that apply.
“In this situation, systems may need to evolve in time. Hence, their potential shortcomings may not be apparent from the beginning. On the contrary, ensuring accountability may require a continuous process of auditing and mitigation. While the protocols for auditing are better understood, tools for mitigation are generally scarce”.
What kind of risks are we talking about? Potentially, for example, a system that produces unreliable or simply wrong outputs, an unfair model that penalises certain clients or types of client over others and opens up legal risks, or one whose outputs can be used to breach privacy protections.
While pointing out that precautionary measures can and should be taken to mitigate risk up front, the Barcelona team explored methods for reacting to mitigate risks discovered during auditing: “We foresee three such tools that may be used to mitigate risks in a company deployment environment, namely model retraining and fine-tuning, model wrappers, and model copies.”
Most literature on risk mitigation discusses retraining the ML model; However, that depends upon having access to both the training data and an understanding of the internals of the algorithm. In many real-life cases, one or both of these resources can be outside a company’s control, insofar as the ML algorithm acts as a “black box” and the training data (or parts thereof) have been supplied by an external provider, rendering the retraining option unavailable or, at best, considerably more of a challenge.
Alternatively, it is possible to “wrap” the model with additional functionality to attempt to address the issue identified by auditing. In this case, the essential system is unchanged, but an extra element is added to address the risk. However, the authors explained that this method still requires access to the training data. As a result, the authors focused on model copies, which can be used without either the training data or understanding of the algorithm’s inner workings.
“Copying refers to the process of building a functional model which is equivalent in its decision behaviour to another. Copies are useful when it is not possible to retrain the model nor to build a wrapper. This happens when one does not have access to the training data, or the system is either very complex or not accessible for inspection. Besides, copies can also be used even when one or both components are available,” they wrote.
The paper demonstrates both the value of creating a copy – insofar as the process creates a functional replica into which the company has more visibility and control – and techniques to go about it without access to the training data of the original algorithm. The process is aided considerably because there is already an original with known inputs and outcomes, so that the model builders are, to a great degree, reverse engineering a solution rather than creating it from nothing.
They give the example of a credit-scoring agency in Mexico, highlighting how copies that replicate the process and outcomes of the original very closely can be used to address a variety of risks associated with the original. Ultimately, as the paper points out, creating a copy can be “an agile, cost-effective tool to mitigate risks in cases where the training data are not accessible and the model internals unknown.”